Regresja liniowa w Excelu: klucz do zrozumienia i prognozowania danych
- Regresja liniowa modeluje zależności między zmienną zależną (Y) a niezależną (X) w Excelu
- Analizę można przeprowadzić za pomocą dodatku Analysis ToolPak lub funkcji REGLINP
- Kluczowe wskaźniki do interpretacji to współczynnik R kwadrat, współczynniki równania i wartość p
- Wizualizacja wyników na wykresie punktowym z linią trendu jest niezbędna do prezentacji
- Praktyczne zastosowanie regresji liniowej pozwala na prognozowanie i podejmowanie lepszych decyzji
Dlaczego prognozowanie w Excelu jest łatwiejsze, niż myślisz? Wprowadzenie do regresji liniowej
Wielu z nas kojarzy analizę statystyczną z czymś skomplikowanym i dostępnym tylko dla ekspertów. Nic bardziej mylnego! Excel oferuje potężne narzędzia, które sprawiają, że nawet zaawansowane techniki, takie jak regresja liniowa, stają się dostępne i intuicyjne. Regresja liniowa to prosty, ale niezwykle skuteczny sposób na odkrycie, jak jedna zmienna wpływa na drugą. To fundament, na którym możemy budować prognozy, analizować trendy i podejmować lepsze, oparte na danych decyzje. Dzięki niemu możemy zobaczyć ukryte wzorce w naszych danych, które w innym przypadku pozostałyby niezauważone.Co to jest regresja liniowa i jakie problemy biznesowe pomoże Ci rozwiązać?
W najprostszych słowach, regresja liniowa to metoda statystyczna, która pomaga nam zrozumieć i opisać związek między dwiema zmiennymi. Jej głównym celem jest znalezienie matematycznego wzoru, który najlepiej opisuje, jak zmiana jednej zmiennej wpływa na zmianę drugiej. Wyobraź sobie, że chcesz przewidzieć, jak duża sprzedaż czeka Cię w przyszłym miesiącu. Regresja liniowa może pomóc Ci to oszacować, analizując na przykład, jak wydatki na reklamę wpływają na osiągane wyniki. Możemy dzięki niej prognozować sprzedaż, analizować wpływ inwestycji w marketing, przewidywać ceny produktów, a nawet oceniać, jak doświadczenie pracownika wpływa na jego wydajność. To narzędzie, które przekłada dane na konkretne wnioski biznesowe.
Zmienna zależna (Y) i niezależna (X) – jak je poprawnie zidentyfikować w swoich danych?
Zanim zagłębimy się w analizę, musimy zrozumieć kluczowe pojęcia: zmienną zależną (Y) i zmienną niezależną (X). Zmienna niezależna (X) to ta, którą możemy kontrolować lub która jest czynnikiem zewnętrznym, a jej zmiana ma potencjalny wpływ. Zmienna zależna (Y) to ta, której wartość chcemy wyjaśnić lub przewidzieć, a która zależy od zmiennej niezależnej. Pomyśl o tym tak: jeśli chcemy sprawdzić, jak wydatki na reklamę (X) wpływają na sprzedaż (Y), to wydatki na reklamę są naszą zmienną niezależną, a sprzedaż zależną. Prawidłowe zidentyfikowanie tych zmiennych jest absolutnie kluczowe dla powodzenia całej analizy.
Dwa sprawdzone sposoby na regresję w Excelu: kiedy wybrać funkcję REGLINP, a kiedy Analysis ToolPak?
Excel daje nam dwie główne ścieżki do przeprowadzenia analizy regresji liniowej. Pierwsza to dodatek "Analysis ToolPak", który jest częścią Excela, ale często wymaga ręcznej aktywacji. Jest to opcja bardziej rozbudowana, generująca szczegółowy raport, idealna dla osób, które chcą dokładnie zrozumieć wszystkie aspekty analizy. Druga metoda to funkcja `REGLINP` (w angielskiej wersji Excela `LINEST`). Jest to funkcja tablicowa, która pozwala na szybkie uzyskanie kluczowych współczynników regresji. Wybór zależy od Twoich potrzeb: jeśli potrzebujesz kompleksowego raportu i dopiero zaczynasz, Analysis ToolPak będzie świetnym wyborem. Jeśli cenisz sobie szybkość i potrzebujesz tylko podstawowych danych, `REGLINP` może okazać się bardziej efektywny.
Metoda 1: Regresja liniowa krok po kroku z użyciem dodatku Analysis ToolPak
Dodatek Analysis ToolPak to prawdziwy kombajn analityczny w Excelu. Choć wymaga kilku dodatkowych kliknięć do aktywacji, oferuje on niezwykle szczegółowy raport, który przeprowadzi nas przez wszystkie meandry analizy regresji. Jest to doskonały wybór dla każdego, kto chce nie tylko wykonać analizę, ale także dogłębnie zrozumieć jej wyniki.
Jak włączyć dodatek Analysis ToolPak? Szybka instrukcja aktywacji
- Otwórz program Excel.
- Przejdź do zakładki "Plik" (File).
- Wybierz "Opcje" (Options).
- W oknie "Opcje programu Excel" wybierz "Dodatki" (Add-Ins).
- Na dole okna, obok "Zarządzaj: Dodatki programu Excel" (Manage: Excel Add-ins), kliknij "Przejdź" (Go...).
- W nowym oknie zaznacz pole wyboru "Analysis ToolPak" i kliknij "OK".
Po wykonaniu tych kroków, w zakładce "Dane" (Data) powinna pojawić się nowa grupa o nazwie "Analiza" (Analysis), zawierająca przycisk "Analiza danych" (Data Analysis). To właśnie tam znajdziemy narzędzie do regresji.
Przeprowadzamy analizę: jak poprawnie wypełnić okno dialogowe "Regresja"?
- Przygotuj dane: upewnij się, że Twoje dane dla zmiennej zależnej (Y) i zmiennej niezależnej (X) znajdują się w osobnych kolumnach i mają tę samą liczbę wierszy.
- Przejdź do zakładki "Dane" (Data) i kliknij "Analiza danych" (Data Analysis).
- Z listy dostępnych narzędzi analitycznych wybierz "Regresja" (Regression) i kliknij "OK".
- W oknie dialogowym "Regresja" uzupełnij następujące pola:
- "Zakres wejściowy Y" (Input Y Range): Kliknij w pole i zaznacz myszką zakres komórek zawierających Twoją zmienną zależną (Y).
- "Zakres wejściowy X" (Input X Range): Podobnie, zaznacz zakres komórek ze zmienną niezależną (X).
- "Etykiety" (Labels): Zaznacz to pole, jeśli pierwszy wiersz zaznaczonych zakresów zawiera nagłówki kolumn (nazwy zmiennych).
- "Poziom ufności" (Confidence Level): Domyślnie ustawiony jest na 95%. Możesz go zmienić, jeśli potrzebujesz innego poziomu pewności.
- "Opcje wyjścia" (Output Options): Tutaj wybierasz, gdzie ma zostać wygenerowany raport. Najczęściej wybierane opcje to "Nowy arkusz roboczy" (New Worksheet Ply) lub "Nowy skoroszyt" (New Workbook).
- Po poprawnym wypełnieniu wszystkich pól, kliknij "OK", aby Excel wygenerował raport regresji.
Generowanie raportu – czyli co Excel właśnie dla Ciebie policzył?
Po kliknięciu "OK", Excel przeniesie nas do wybranego miejsca (np. nowego arkusza) i przedstawi kompleksowy raport z przeprowadzonej analizy. Raport ten składa się z kilku kluczowych sekcji. Znajdziemy tam "Statystyki regresji", które dają ogólny obraz dopasowania modelu, "Analizę wariancji (ANOVA)", która ocenia ogólną istotność modelu, oraz najważniejszą dla nas sekcję "Współczynniki", zawierającą szczegółowe informacje o poszczególnych zmiennych. Każda z tych części dostarcza cennych informacji, które pomogą nam zrozumieć zależności w naszych danych.
Jak czytać i rozumieć raport z analizy regresji? Kluczowe wskaźniki pod lupą
Samo wygenerowanie raportu to dopiero początek drogi. Prawdziwa wartość analizy regresji tkwi w umiejętności interpretacji uzyskanych wyników. Musimy wiedzieć, co oznaczają poszczególne liczby, aby móc wyciągnąć poprawne wnioski. Przyjrzyjmy się najważniejszym wskaźnikom, które znajdziemy w raporcie z Excela.
Statystyki regresji: Co tak naprawdę mówi Ci współczynnik R kwadrat (R²)?
Jednym z najważniejszych wskaźników, na który zwracamy uwagę, jest współczynnik R kwadrat, często oznaczany jako R² lub "R Square". Mówi nam on, jaki procent zmienności zmiennej zależnej (Y) jest wyjaśniany przez nasz model regresji, czyli przez zmienną niezależną (X). Im bliższa jedności jest wartość R², tym lepiej nasz model opisuje dane. Na przykład, wartość R² na poziomie 0,99 oznacza, że aż 99% zmian w zmiennej Y można wyjaśnić zmianami w zmiennej X. To bardzo silny sygnał, że nasz model dobrze odwzorowuje obserwowany trend. Pamiętaj jednak, że wysoki R² nie zawsze gwarantuje idealny model zawsze warto spojrzeć też na inne wskaźniki i kontekst.
Tabela współczynników: jak zinterpretować nachylenie i wyraz wolny, by zrozumieć zależność?
W tabeli współczynników znajdziemy dwie kluczowe wartości: nachylenie (slope) i wyraz wolny (intercept). Równanie naszej linii regresji ma postać y = ax + b, gdzie 'a' to nachylenie, a 'b' to wyraz wolny. Nachylenie ('a') informuje nas, o ile średnio zmieni się wartość zmiennej zależnej (Y), gdy zmienna niezależna (X) wzrośnie o jedną jednostkę. Wyraz wolny ('b') to przewidywana wartość Y, gdy X wynosi zero. Na przykład, jeśli regresja sprzedaży (Y) od wydatków na reklamę (X) da nam równanie y = 2x + 100, oznacza to, że każde dodatkowe 100 zł wydane na reklamę zwiększa sprzedaż średnio o 200 zł, a przy zerowych wydatkach na reklamę sprzedaż wyniosłaby 100 zł.
Istotność statystyczna: Czym jest tajemnicza "Wartość P" i dlaczego powinna być niska?
Kolejnym niezwykle ważnym wskaźnikiem jest "Wartość P" (P-value). Mówi nam ona o istotności statystycznej naszego modelu. Mówiąc prościej, określa prawdopodobieństwo, że zaobserwowana zależność między zmiennymi jest dziełem przypadku. Standardowo przyjmuje się, że jeśli wartość P jest niższa niż 0,05 (czyli 5%), to zależność jest statystycznie istotna. Oznacza to, że z 95% pewnością możemy stwierdzić, że związek między zmiennymi nie jest przypadkowy. Niska wartość P jest więc pożądana, bo potwierdza, że nasz model ma realne podstawy. Wysoka wartość P sugeruje, że związek może być przypadkowy i nie powinniśmy na nim polegać.
Analiza wariancji (ANOVA) w raporcie – kiedy warto na nią spojrzeć?
Analiza wariancji, czyli ANOVA, jest częścią raportu regresji, która dostarcza nam informacji o ogólnej istotności całego modelu regresji. W przypadku prostych regresji liniowych, gdzie mamy tylko jedną zmienną niezależną, często wystarczy nam ocena R kwadrat i wartości P dla poszczególnych współczynników. Jednak w bardziej złożonych modelach, z wieloma zmiennymi niezależnymi, ANOVA jest kluczowa do oceny, czy model jako całość jest statystycznie istotny. Podpowiada nam, czy nasz model lepiej wyjaśnia zmienność danych niż model, który zakłada brak zależności.
Metoda 2: Szybka regresja z funkcją REGLINP – dla tych, co cenią czas
Jeśli potrzebujesz szybkich wyników i nie chcesz generować pełnego, rozbudowanego raportu, funkcja `REGLINP` jest dla Ciebie. Jest to funkcja tablicowa, która pozwala na błyskawiczne obliczenie kluczowych parametrów regresji liniowej. Jest to świetne rozwiązanie, gdy liczy się czas, a potrzebujemy jedynie podstawowych danych do dalszych analiz lub wizualizacji.
Składnia funkcji REGLINP – jak poprawnie ją zapisać?
Funkcja `REGLINP` ma następującą składnię: `=REGLINP(znane_y; znane_x; stała; statystyki)`. Przyjrzyjmy się poszczególnym argumentom:
- `znane_y`: Jest to zakres komórek zawierających dane zmiennej zależnej (Y), którą chcemy przewidzieć.
- `znane_x`: To zakres komórek z danymi zmiennej niezależnej (X), która ma wpływać na Y.
- `stała` (argument opcjonalny): Jeśli ustawimy go na PRAWDA (TRUE), Excel obliczy wyraz wolny ('b') w równaniu prostej. Jeśli ustawimy na FAŁSZ (FALSE), wyraz wolny zostanie ustawiony na zero. Domyślnie jest to PRAWDA.
- `statystyki` (argument opcjonalny): Ustawienie tego argumentu na PRAWDA (TRUE) spowoduje, że funkcja zwróci dodatkowe statystyki regresji (jak R kwadrat, błędy standardowe itp.). Ustawienie na FAŁSZ (FALSE) zwróci tylko współczynnik nachylenia i wyraz wolny. Domyślnie jest to FAŁSZ.
Formuła tablicowa w praktyce: jak ją wprowadzić, by uniknąć błędu #VALUE!
Funkcja `REGLINP` jest funkcją tablicową, co oznacza, że zwraca wiele wartości jednocześnie. Aby poprawnie ją wprowadzić i uniknąć błędów, takich jak #VALUE!, należy postępować według poniższych kroków:
- Najpierw zaznacz pusty zakres komórek, który będzie wystarczająco duży, aby pomieścić wszystkie zwracane wartości. Dla prostej regresji liniowej, gdy chcemy uzyskać pełne statystyki (argument `statystyki` ustawiony na PRAWDA), potrzebujemy obszaru 5 wierszy na 2 kolumny.
- Następnie, w pasku formuły, wpisz formułę, np. `=REGLINP(A1:A10; B1:B10; PRAWDA; PRAWDA)`, gdzie A1:A10 to zakres zmiennej Y, a B1:B10 to zakres zmiennej X.
- Teraz kluczowy krok: zamiast naciskać samo Enter, zatwierdź formułę kombinacją klawiszy Ctrl+Shift+Enter. W starszych wersjach Excela jest to konieczne. W nowszych wersjach Microsoft 365, wystarczy samo Enter, a Excel sam rozpozna, że jest to formuła tablicowa.
Jakie informacje zwraca funkcja REGLINP i jak je odczytać?
Gdy argument `statystyki` funkcji `REGLINP` ustawiony jest na PRAWDA, funkcja zwraca szereg wartości, które należy odczytywać w ściśle określonej kolejności. Są to zazwyczaj:
- Współczynnik nachylenia (slope): Wartość 'a' z równania y = ax + b.
- Wyraz wolny (intercept): Wartość 'b' z równania y = ax + b.
- Współczynnik R kwadrat (R²): Miara dopasowania modelu.
- Standardowy błąd estymacji: Miara rozproszenia błędów wokół linii regresji.
- Liczba stopni swobody: Związana z liczbą obserwacji i liczbą zmiennych.
- Sumy kwadratów regresji i reszt: Informacje o wariancji wyjaśnionej i niewyjaśnionej przez model.
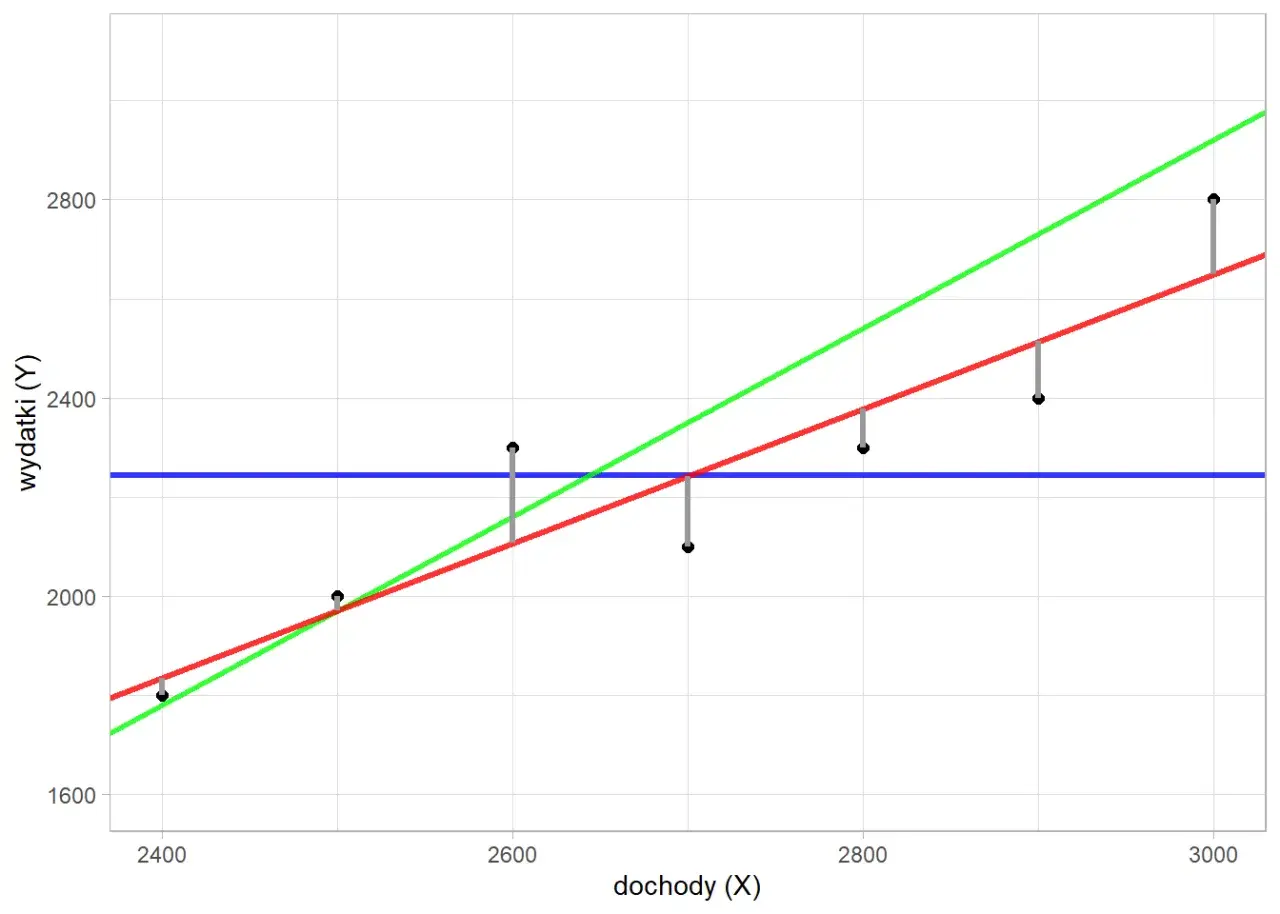
Wizualizacja ma znaczenie! Jak stworzyć wykres regresji liniowej w Excelu?
Dane liczbowe mogą być czasami trudne do przyswojenia. Dlatego wizualizacja wyników analizy regresji jest tak ważna. Wykres punktowy z dodaną linią trendu pozwala nam natychmiast zobaczyć, jak dobrze model opisuje dane, i ułatwia prezentację wniosków. Excel oferuje proste narzędzia do tworzenia takich wykresów.
Tworzenie wykresu punktowego (XY) – pierwszy krok do wizualizacji danych
- Zaznacz kolumny zawierające dane dla zmiennej niezależnej (X) i zmiennej zależnej (Y). Ważne, aby były one obok siebie lub abyś wiedział, które dane wybrać.
- Przejdź do zakładki "Wstawianie" (Insert) na górnym pasku Excela.
- W grupie "Wykresy" (Charts) znajdź ikonę "Wykres punktowy (XY)" (Scatter) i kliknij ją. Wybierz typ wykresu, który najlepiej odpowiada Twoim potrzebom, zazwyczaj jest to "Wykres punktowy z samymi znacznikami" (Scatter with only Markers).
Po wykonaniu tych kroków, na arkuszu pojawi się wykres przedstawiający rozkład Twoich punktów danych. To dopiero początek naszej wizualizacji.
Dodawanie linii trendu: jak automatycznie narysować prostą regresji?
- Kliknij na utworzony wykres punktowy, aby go zaznaczyć. Powinny pojawić się dodatkowe zakładki kontekstowe związane z projektowaniem wykresu.
- Kliknij znak "+" (Elementy wykresu / Chart Elements), który zazwyczaj pojawia się obok zaznaczonego wykresu, lub przejdź do zakładki "Projektowanie wykresu" (Chart Design) i wybierz opcję "Dodaj element wykresu" (Add Chart Element).
- Z rozwijanej listy wybierz "Linia trendu" (Trendline), a następnie zdecyduj się na "Liniową" (Linear), jeśli wykonujesz regresję liniową.
Excel automatycznie dopasuje i narysuje na wykresie linię, która najlepiej reprezentuje zależność między Twoimi punktami danych zgodnie z modelem regresji liniowej.
Wyświetlanie równania i R² na wykresie – szybki sposób na prezentację wyników
- Po dodaniu linii trendu, kliknij na nią prawym przyciskiem myszy, a następnie wybierz opcję "Formatuj linię trendu" (Format Trendline).
- Po prawej stronie ekranu otworzy się panel formatowania. W tym panelu znajdź i zaznacz opcje: "Wyświetl równanie na wykresie" (Display Equation on chart) oraz "Wyświetl wartość R-kwadrat na wykresie" (Display R-squared value on chart).
Dzięki tym prostym krokom, na wykresie pojawią się zarówno równanie linii regresji, jak i współczynnik R kwadrat. To ogromne ułatwienie, ponieważ pozwala na szybką, wizualną ocenę dopasowania modelu i zrozumienie zależności bez konieczności zagłębiania się w szczegółowy raport.
Najczęstsze błędy i pułapki – na co uważać podczas analizy regresji w Excelu?
Regresja liniowa, mimo swojej prostoty, ma swoje ograniczenia i wymaga ostrożności. Istnieje kilka typowych błędów i pułapek, na które warto uważać, aby nasze analizy były wiarygodne i prowadziły do właściwych wniosków. Świadomość tych potencjalnych problemów jest równie ważna, co umiejętność wykonania samej analizy.
Nieliniowa zależność – co zrobić, gdy punkty na wykresie nie układają się w linię?
Podstawowym założeniem regresji liniowej jest to, że zależność między zmiennymi jest liniowa, czyli można ją opisać prostą linią. Jeśli po narysowaniu wykresu punktowego widzimy, że punkty układają się w wyraźny łuk, krzywą lub inny nieliniowy wzorzec, oznacza to, że regresja liniowa może nie być najlepszym modelem do opisu tej zależności. W takich sytuacjach warto rozważyć inne typy regresji, na przykład regresję wielomianową, lub spróbować transformacji danych, aby uzyskać bardziej liniowy związek.
Błędna interpretacja R² – kiedy wysoki wynik może być mylący?
Wysoki współczynnik R kwadrat (bliski 1) jest zazwyczaj dobrym znakiem, ale nie zawsze oznacza, że nasz model jest idealny lub że związek między zmiennymi jest przyczynowo-skutkowy. Możliwe jest, że mamy do czynienia z tzw. korelacją pozorną, czyli sytuacją, gdy dwie zmienne wydają się silnie powiązane, ale w rzeczywistości nie ma między nimi bezpośredniego związku przyczynowego, a obie są zależne od jakiegoś trzeciego czynnika. Zawsze należy analizować R kwadrat w kontekście biznesowym i teoretycznym, a nie traktować go jako jedynego wyznacznika jakości modelu.
Ignorowanie założeń modelu liniowego – dlaczego to ryzykowne?
Regresja liniowa opiera się na kilku kluczowych założeniach, takich jak liniowość zależności, niezależność błędów (reszt), stała wariancja błędów (homoscedastyczność) i normalność rozkładu błędów. Ignorowanie tych założeń może prowadzić do błędnych wniosków i niewiarygodnych wyników. Na przykład, jeśli błędy nie są niezależne, nasze oszacowania współczynników mogą być obciążone. W przypadku wątpliwości co do spełnienia założeń, warto pogłębić wiedzę na ten temat lub skonsultować się ze specjalistą, aby upewnić się, że nasze analizy są poprawne.
Praktyczne zastosowania: kiedy regresja liniowa w Excelu staje się potężnym narzędziem?
Regresja liniowa w Excelu to nie tylko teoretyczne ćwiczenie. To potężne narzędzie, które znajduje szerokie zastosowanie w praktyce biznesowej, pomagając podejmować lepsze decyzje i optymalizować procesy. Oto kilka przykładów, jak można ją wykorzystać:
Prognozowanie sprzedaży na podstawie wydatków na reklamę
Jednym z najczęstszych zastosowań jest prognozowanie sprzedaży. Analizując historyczne dane, możemy zbudować model regresji, który pokaże, jak wydatki na reklamę (zmienna niezależna X) wpływają na osiągane wyniki sprzedaży (zmienna zależna Y). Dzięki temu możemy ocenić efektywność naszych kampanii marketingowych i podejmować świadome decyzje dotyczące alokacji budżetu reklamowego, maksymalizując zwrot z inwestycji.
Analiza wpływu ceny na liczbę sprzedanych produktów
Regresja liniowa może być również nieoceniona w strategiach cenowych. Badając, jak zmiana ceny produktu (X) wpływa na popyt, czyli liczbę sprzedanych sztuk (Y), możemy określić optymalny poziom cenowy. Pozwala to na maksymalizację zysków, jednocześnie dbając o utrzymanie konkurencyjności na rynku i zaspokojenie potrzeb klientów.
Przeczytaj również: Co oznacza Excel? Zrozumienie symboli i funkcji w arkuszu kalkulacyjnym
Badanie zależności między doświadczeniem pracownika a jego wydajnością
W obszarze zarządzania zasobami ludzkimi regresja liniowa może pomóc w analizie zależności między doświadczeniem zawodowym pracownika (np. liczba lat pracy, X) a jego wydajnością lub poziomem wynagrodzenia (Y). Takie analizy mogą wspierać tworzenie sprawiedliwych systemów płacowych, identyfikować obszary rozwoju pracowników i optymalizować procesy rekrutacyjne, opierając się na danych, a nie tylko na intuicji.